Cuckoo Hashing
Cuckoo Hashing是一种用”布谷鸟”的方法解决哈希冲突的算法,其最坏的查找时间是O(1)。
Cuckoo指的是“布谷鸟”,为什么是“布谷鸟”呢?因为有一种布谷鸟会把蛋生在别人的鸟巢里,然后把别人家的蛋推走。Cuckoo Hashing使用类似的方法来解决哈希冲突,如果在插入数据时发现冲突了,就将冲突位置上的数据搬走。
算法
丹麦的两位教授在2001年首先发表论文阐述了该算法。paper
论文中一段代码阐述了算法的核心部分:
插入x时,如果找到就返回;否则进入循环,循环次数最大为MaxLoop。
在循环里,如果T1表中x的位置为空,插入x到T1表返回;否则,将x和当前位置上的指交换;
此时x变成被挤出来的值,尝试同样方法插入到T2;直到找到空余的位置。
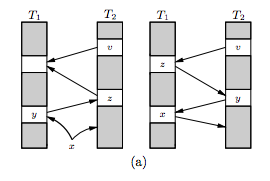
如下图,x插入T1后,y被推到T2表,又导致了z从T2被推出来,直到z在T1找到了空的位置。
实现
RocksDB把HashCuckoo用作Memtable的一个可选算法,其他算法还包括SkipList, HashLinkList, HashSkipList。只有HashCuckoo的最坏查找时间是O(1),在某些使用上有一定的优势。
下面分析Memtable主要的两个接口Get和Insert。
|
|
HashCuckoo使用了10个(hash_functioncount)哈希函数来解决冲突。
搜索key键值,依次遍历这个10个哈希函数,依次判断每一个哈希结果的位置是否为空;如果不为空,判断该位置键值是否与key相同,相同则返回;不同则继续下一次哈希。如果位置为空则退出循环,因为HashCuckoo的插入是从最低的哈希函数开始寻找位置的,如果空说明该键值不存在。退出循环在backup哈希表里进行查找。
|
|
插入流程相对查找流程较为复杂,前面的论文中以两个哈希函数来解决冲突,RocksDB使用10个哈希函数,所以插入时产生冲突了会出现树形结构的遍历,每个树节点都有10个子节点。FindCuckooPath函数就是使用BFS广度优先搜索在树形结构遍历中查找到空的位置,并记录下查找路径需要推出的位置cuckoopath。
FindCuckooPath的实现在下面进行分析。如果FindCuckooPath查找不到空的位置,就尝试在backup_table里面进行插入。如果FindCuckooPath返回true,后面就根据FindCuckooPath填充的cuckoopath依次将路径上的键值往后一个位置移动,最后插入新key。
|
|
QuickInsert快速的搜索key对应的10个哈希位置是否有位置可以插入。
如果没有查找到,那么就要开始使用BFS算法进行搜索。其中CuckooStep用来记录可以回退的步骤,stepbuffer则保存了BFS搜索的队列。
将搜索key的10个哈希位置都入到队列,后面While循环进入BFS搜索,每次从队列头取出一个步骤,如果步骤的深度已经超过cuckoo_path_maxdepth返回。如果该位置的key和搜索的key相同,则出现了循环,跳过该次搜索。以上条件都不满足,将改步骤的其他哈希位置(由于cuckooHash总是从最低位的哈希函数开始插入,我们只需要从大于当前哈希的函数的位置开始搜索)入到队列。
一旦找到了一个空的哈希位置,从stepbuffer中回溯出搜索的路径存到cuckoo_path。